主页 > imtoken钱包下 > 以太坊数据结构的存储方式有哪些?以太坊数据结构及存储分析
以太坊数据结构的存储方式有哪些?以太坊数据结构及存储分析
以太坊数据结构的存储方式有哪些?以太坊数据结构及存储分析
一、概述
在以太坊中,数据存储大致分为三部分:状态数据、区块链和底层数据。

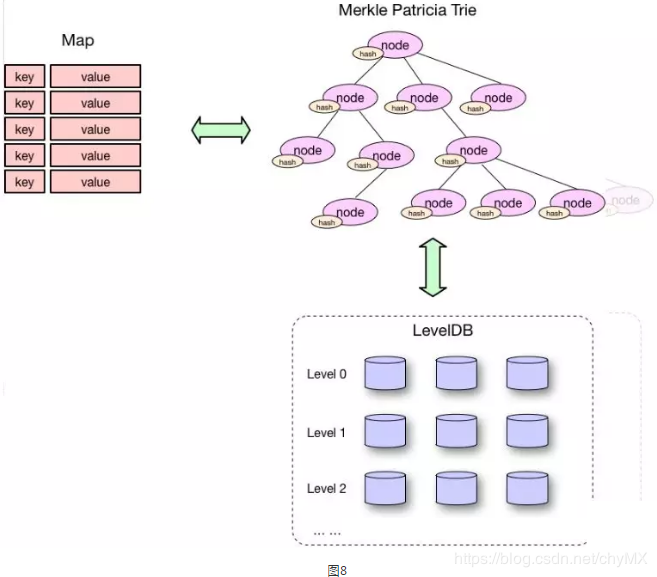
其中,底层数据存储了以太坊中的所有数据,存储形式为[k,v]键值对。 当前使用的数据库是LevelDB; 所有与交易和操作相关的数据都存储在链上; StateDB是用来管理账户的,每个账户都是一个stateObject。
2. 块部分
块结构:
区块链是以太坊的核心之一。 所有交易和结构都存储在块中。 接下来我们看一下以太坊中的区块结构。
以太坊中所有的结构定义基本上都可以在core/types中找到,区块结构定义在block.go中
中间:


受比特币区块链数据结构的影响,我认为区块可以简单的分成两部分:head和body。 但是看了以太坊的源码后,发现以太坊并不是这样设计的。 在block.go中,以太坊区块链的区块结构定义为:

可以看到body+head!=block。另外block.go文件中定义了很多结构,比如for
extblock 用于协议,storageblock 用于存储等。

可以看出header结构的使用频率很高,我们来看看header结构是怎么定义的:

Header成员变量的解释如下:
ParentHash:指向父块(parentBlock)的指针。 除创世块外,每个块都有一个且只有一个父块。
Coinbase:挖出这个区块的矿工地址。 用于分配奖励。
UncleHash:Block结构的成员叔叔的哈希值。注意这个字段是一个Header编号
团体。
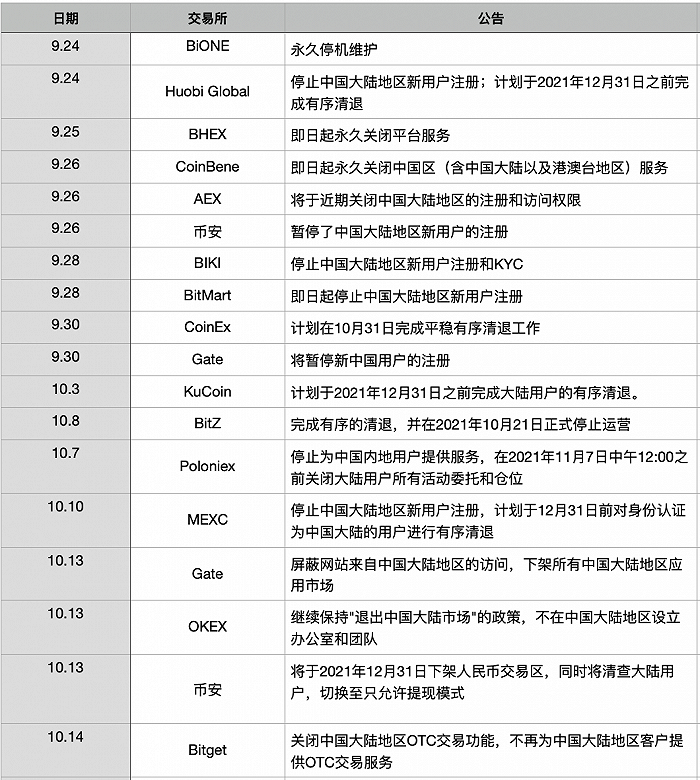
Root:StateDB中“state Trie”根节点的哈希值。 在Block中,每个账户都由一个stateObject对象表示,账户由Address唯一标识,其信息在相关交易(Transaction)执行过程中被修改。 所有的账户对象都可以一个一个插入到一个Merkle-PatricaTrie (MPT)结构中,形成一个“状态
特里”。
TxHash:Block中“tx Trie”根节点的哈希值。 全部在Block的成员变量transactions中
tx对象被一个一个插入到一个MPT结构中,形成一个“tx Trie”。
ReceiptHash:Block中“Receipt Trie”根节点的哈希值。 Block的所有Transaction执行完毕后,会生成一个Receipt数组,将这个数组中的所有Receipt逐一插入到一个MPT结构中,形成一个“Receipt Trie”。 (比特币区块中有一棵 Merkle 树用于存储交易,而以太坊中有三棵 MP 树,其功能各不相同)
Bloom:布隆过滤器(Filter),用于快速判断一个参数Log对象是否存在于一组已知的Log集合中。
难度:区块的难度。 区块的难度由共识算法根据父区块的时间和难度计算得出,并将应用于区块的“挖矿”阶段。

Number:区块序号。 块的编号等于其父块的编号+1。
时间:区块“应该”被创建的时间。 由共识算法决定,一般来说要么等于parentBlock.Time + 10s,要么等于当前系统时间。
GasLimit:区块内所有Gas消耗量的理论上限。 该值在创建块时设置,并与父块相关。 具体是根据父块的GasUsed和GasLimit * 2/3的关系来计算的。
GasUsed:区块中所有交易实际消耗的Gas总和。
Nonce:一个 64 位的哈希数,用于“挖矿”。
块存储:
区块的数据最终以[k,v]的形式存储在数据库中,数据库在主机中的存储位置为:
数据目录/geth/链数据。 具体代码在core/database_util.go中。存储block时,head和
身体是分开存放的。

以 writeHeader 为例:

存储header时,content部分的key为:prefix+num(uint64 big endian)+hash; 值是块
标头的 rlp 编码。 其余模块存储方式类似:

database_util.go 文件中也定义了各种前缀。 值得注意的是,该文件中还有一组函数用于仅存储区块头,这应该会提高以太坊的灵活性。

3.交易部分
交易部分内容较多,已写在专门的文档中,请查看之前的内容。
4. Merkle-Patricia Trie
Merkle-Patricia Trie 简介:
以太坊使用的Merkle-PatriciaTrie (MPT)结构源自Trie结构并继承
借鉴PatriciaTrie和MerkleTree的优点,结合内部数据的特点,设计了全新的节点体系和插入加载机制。
Trie,也称为字典树或前缀树,是一种搜索树。 它与平衡二叉树的主要区别包括:每个节点数据携带的key不会存储在Trie节点中,而是通过节点在整个树结构中的位置来体现; 同一父节点的子节点,父节点共享的key作为各自key的前缀,所以根节点key为空; 要存储的数据只存储在叶子节点中,非叶子节点帮助形成叶子节点key的前缀。 下图来自wiki-Trie,展示了一个简单的Trie结构。

PatriciaTrie,也称为 RadixTree 或紧凑前缀树,是一种空间使用优化的 Trie。 与Trie不同的是,如果PatriciaTrie中存在一个只有一个子节点的父节点,那么父节点将与其子节点合并。 这减少了 Trie 中不必要的深度并大大加快了节点的搜索速度。
MerkleTree,也叫哈希树,是密码学中的一个概念。 注意理论上不一定是Trie。 在哈希树中,叶子节点的标签是其关联数据块的哈希值,而非叶子节点的标签是其所有子节点的标签拼接而成的字符串的哈希值。 哈希树的优点是可以快速高效地验证大量的数据内容。 假设一棵哈希树中有n个叶子节点,如果要验证其中一个叶子节点是否正确——即节点数据属于源数据集且数据本身是否完整,则时间复杂度需要的hash计算是O(log(n)),相比之下,hash list需要时间复杂度为O(n)的hash计算,hash
tree的表现无疑是优秀的。

上图来自 wiki-MerkleTree,展示了一个简单的二叉哈希树。 四个有效数据块 L1-L4。 分别关联到一个叶节点。 Hash0-0和Hash0-1分别等于数据块L1和L2的哈希值,Hash0等于Hash0-0和Hash0-1组合形成的新字符串的哈希值,以此类推在。 根节点topHash的标号等于Hash0和Hash1拼接成的新字符串的哈希值。 比特币在存储交易时使用这种数据结构。
实施部分
MPT的相关代码在tire文件夹中。
Node.go中定义了四种类型的节点,分别是:

其中nodeFlag用于存放创建/修改节点时的缓存数据。

fullNode 是一个父(分支)节点,可以携带多个子节点。 它有一个容量为17的节点数组成员变量Children,数组中的前16个槽对应十六进制(hex)的0-9a-f,所以对于每一个子节点,根据它的key值为十六进制的值可以将Children数组的第一位挂载到Children数组的某个位置,fullNode本身不需要额外的key变量; Children 数组的第 17 位保留用于 fullNode 的数据部分。 fullNode显然继承了原来trie的特点,每个父节点最多有16个分支,这其中也包含了基于整体效率的考虑。
shortNode 是只有一个子节点的父(分支)节点。 它的成员变量Val指向一个子节点,成员Key是一个任意长度的字符串(字节数组[]byte)。 显然,shortNode的设计体现了PatriciaTrie的特点。 通过合并只有一个子节点的父节点及其子节点来缩短trie的深度。 结果是某些节点将具有更长的密钥。
valueNode 充当 MPT 的叶节点。 它实际上是字节数组 []byte 的别名,没有孩子。 在使用中,valueNode是携带数据的RLP哈希值,长度为32字节,将数据的RLP编码值作为valueNode的匹配项存储在数据库中。
这三种类型涵盖了普通 Trie(可能是 PatriciaTrie)的所有节点要求。 当任何[k,v]类型的数据被插入到一个MPT中时,它会以k字符串为路径沿着根向下延伸,在本次插入结束时首先会成为一个valueNode,k会从顶点开始root to the 节点终止的关键路径形式存在。 但是随着其他节点的不断插入和删除,根据MPT结构的要求,原来的节点可能会变成其他节点实现类型,同时MPT会不断变化或合并新的(parent)节点。 例如:
假设一个shortNode S已经有了一个子节点A,现在要插入一个新的子节点B,那么有两种可能,要么新的节点B沿着A的路径继续往下走,这样S的子节点就会更新; 或 S 的密钥被分成两段。 前段作为新的Key赋值给S,分裂出一个新的fullNode作为S的子节点,同时容纳需要更新的B和A。
如果一个fullNode本来只有两个子节点,现在要删除其中一个子节点,这个fullNode会退化成一个shortNode,如果剩下的子节点是shortNode比特币存储形式,可以重新合并。
如果一个shortNode的子节点是叶子节点,同时被删除,那么这个shortNode就会退化为valueNode,成为叶子节点。 像这样的情况还有很多。 只有提前预想这些情况,才能正确实现插入/删除/查找MPT的操作。 当然,所有寻找搜索树结构的操作都不可避免地要用到递归。
hashNode和valueNode一样,也是字符数组[]byte的别名,也是存储32byte的hash值,没有子节点。 不同的是hashNode是fullNode或者shortNode对象的RLP hash值,所以在用法上和valueNode有很大区别。
在MPT中,hashNode几乎不单独存在(有时遍历遇到一个hashNode,往往是因为原节点被折叠),而是以nodeFlag结构体(nodeFlag.hash)成员的形式被fullNode和shortNode间接持有。 一旦fullNode或shortNode的成员变量(包括子结构)发生变化,它们的hashNode就必须更新。 因此在trie.Trie结构体的insert()、delete()等函数的实现中,可以看到除了新建的fullNode和shortNode之外,子结构发生变化的fullNode和shortNode的nodeFlag成员也会也被重置。 hashNode 将被清除。 下次调用trie.Hash()时,自下而上遍历整个MPT时,所有清空的hashNode会被重新赋值。 这样在trie.Hash()结束后,我们就可以得到根节点root的一个hashNode,也就是此时MPT结构的hash值。
Header中的成员变量Root、TxHash、ReceiptHash的生成就来源于此。 显然,hashNode体现了MerkleTree的特点:每个父节点的hash值来自于所有子节点的hash值的组合,一个顶点的hash值可以代表一整个树结构。 hashNode加上前面的fullNode、shortNode、valueNode构成了一个完整的Merkle-PatriciaTrie结构,很好的融合了各种原型结构的优点,值得研究。
用于添加、删除、检查和更改节点的函数都在trie.go 中定义。 在MPT的查找、插入、删除过程中,如果遍历遇到一个hashNode,首先需要从数据库中读取hash值为k的匹配v,然后解码还原v为fullNode或shortNode。 这个过程在代码中叫做resolve。

五。 状态数据库
在系统设计中,在底层数据库模块和业务模型之间,往往需要设置一个本地存储模块。 它面向业务模型,可以根据业务需求灵活设计各种存储格式和单元,同时连接底层数据库。 如果底层数据库(或者第三方API)发生变化,可以大大降低对业务模块的影响。 在以太坊中,StateDB 扮演了这个角色。 它通过大量的 stateObject 对象集合来管理所有“帐户”信息。
StateDB有一个trie.Trie类型的成员trie,也叫storage trie或stte trie。 所有的stateObject对象都存储在这个MPT结构中,每个stateObject对象都以自己的地址(20字节)作为插入节点的Key; 每个 trie 是在块的交易开始执行之前从哈希值 (hashNode) 中恢复的。 另外还有一个map结构,里面也存放了stateObject比特币存储形式,每个stateObject的地址作为map的key。 那么问题来了,这些数据结构之间是什么关系呢?

如上图所示,每当一个stateObject发生变化,即“账户”信息发生变化时,stateObject对象就会更新,stateObject会被标记为dirty,所有的数据变化只存储在map中此时。 当调用 IntermediateRoot() 时,所有标记为脏的 stateObjects 将一起写入 trie。 只有在调用 CommitTo() 时,整个 trie 的内容才会提交到底层数据库。 可以看出这个map是作为本地的一级缓存,trie是二级缓存,底层数据库是三级。 各级数据结构的边界非常清晰。 这样就把数据一层层缓存起来,每一层数据都提交给上层。 时机也是根据业务需求合理选择。
StateDB 还可以管理帐户状态版本。 这个函数使用了几种结构:journal,revision,先看UML图:
其中journal对象是journalEntry的hash,长度不固定,可以任意添加元素。 接口 journalEntry 有多种实现,它描述了从单个账户(账户余额、合约启动次数等)到账户 trie 更改(创建新账户对象、账户注销)和其他最小事件的操作。 revision 结构体用于描述一个'version',它的两个整数成员jd 和journalIndex 基于journal hash 进行操作。

上图简单描述了StateDB中账户状态的版本是如何管理的。 首先,journal hash会随着系统的运行不断增长,记录所有发生过的单元事件; 当某个时刻需要生成一个账户状态版本时,代码中相应的Snapshop()调用会生成一个新的revision对象,记录当前journal hash的长度,以及一个自增1的版本号。
基于以上设计,当发生回滚请求时,只要将所有journalEntry记录根据对应revision中的journalIndex记录在journal hash上,就可以将所有账户回滚到那个状态。 每个 stateObject 在以太坊中管理一个“账户”。 stateObject有一个成员变量data,类型为Accunt结构体,包含账户Ether余额、合约发起次数、最新合约指令集的哈希值、MPT结构体的一个顶点哈希值。
StateObject还有一个Trie类型的成员trie,叫做storage trie,里面存储了一种叫做State的数据。 State与每个账户相关,格式为[Hash, Hash]键值对。 有趣的是,stateObject也有类似StateDB的二级数据缓存机制来缓存和更新这些状态。

stateObject定义了一个名为storage的map结构,用于存储[Hash, Hash]类型的数据对,即State数据。 当 SetState() 调用发生时,存储的内部状态数据被更新,相应地标记为“脏”。 之后,在必要的时候(比如调用updateRoot()),将那些标记为“dirty”的State数据一起写入存储trie中,并在CommitTo()调用时将存储trie中的所有内容一起提交给底层数据库叫。
如果您对区块链数字货币交易平台的价格比较感兴趣,希望找到靠谱正规的区块链数字货币交易平台,那么您可以更深入的咨询我们的官方客服,您可以申请加入我们免费群内官方社群,全是币圈区块链经验丰富的职业玩家和行业大牛,可以帮助大家答疑解惑,共同进步,在币圈赚钱。